Publications
* indicates equal contribution. Full list available on Google Scholar.
2026
CVPR 2026

ShotDirector: Directorially Controllable Multi-Shot Video Generation with Cinematographic Transitions
Xiaoxue Wu, Xinyuan Chen, Yaohui Wang, Yu Qiao
CVPR 2026
[Paper] [Project Page]
Xiaoxue Wu, Xinyuan Chen, Yaohui Wang, Yu Qiao
CVPR 2026
[Paper] [Project Page]
CVPR 2026

VDOT: Efficient Unified Video Creation via Optimal Transport Distillation
Yaohui Wang, Haiyu Zhang, Tianfan Xue, Yu Qiao, Yi Wang, Cunjian Chen, Xinyuan Chen
CVPR 2026
[Paper] [Project Page] [Code]
Yaohui Wang, Haiyu Zhang, Tianfan Xue, Yu Qiao, Yi Wang, Cunjian Chen, Xinyuan Chen
CVPR 2026
[Paper] [Project Page] [Code]
ICLR 2026
CineTrans: Learning to Generate Videos with Cinematic Transitions via Masked Diffusion Models
Xiaoxue Wu, Bingjie Gao, Yu Qiao, Yaohui Wang, Xinyuan Chen
ICLR 2026
[Paper] [Project Page] [Code]
Xiaoxue Wu, Bingjie Gao, Yu Qiao, Yaohui Wang, Xinyuan Chen
ICLR 2026
[Paper] [Project Page] [Code]
Consistent and Controllable Image Animation with Motion Linear Diffusion Transformers
Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Tien-Tsin Wong, Cunjian Chen
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2026
Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Tien-Tsin Wong, Cunjian Chen
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2026
2025
arXiv 2025

Vchitect-2.0: Parallel Transformer for Scaling Up Video Diffusion Models
Weichen Fan, Chenyang Si, Junhao Song, Zhenyu Yang, Yinan He, Long Zhuo, Ziqi Huang, Ziyue Dong, Jingwen He, Dongwei Pan, Yi Wang, Yuming Jiang, Yaohui Wang, Peng Gao, Xinyuan Chen, Hengjie Li, Dahua Lin, Yu Qiao, Ziwei Liu
arXiv:2501.08453, 2025
[Paper] [Code]
Weichen Fan, Chenyang Si, Junhao Song, Zhenyu Yang, Yinan He, Long Zhuo, Ziqi Huang, Ziyue Dong, Jingwen He, Dongwei Pan, Yi Wang, Yuming Jiang, Yaohui Wang, Peng Gao, Xinyuan Chen, Hengjie Li, Dahua Lin, Yu Qiao, Ziwei Liu
arXiv:2501.08453, 2025
[Paper] [Code]
TPAMI 2025
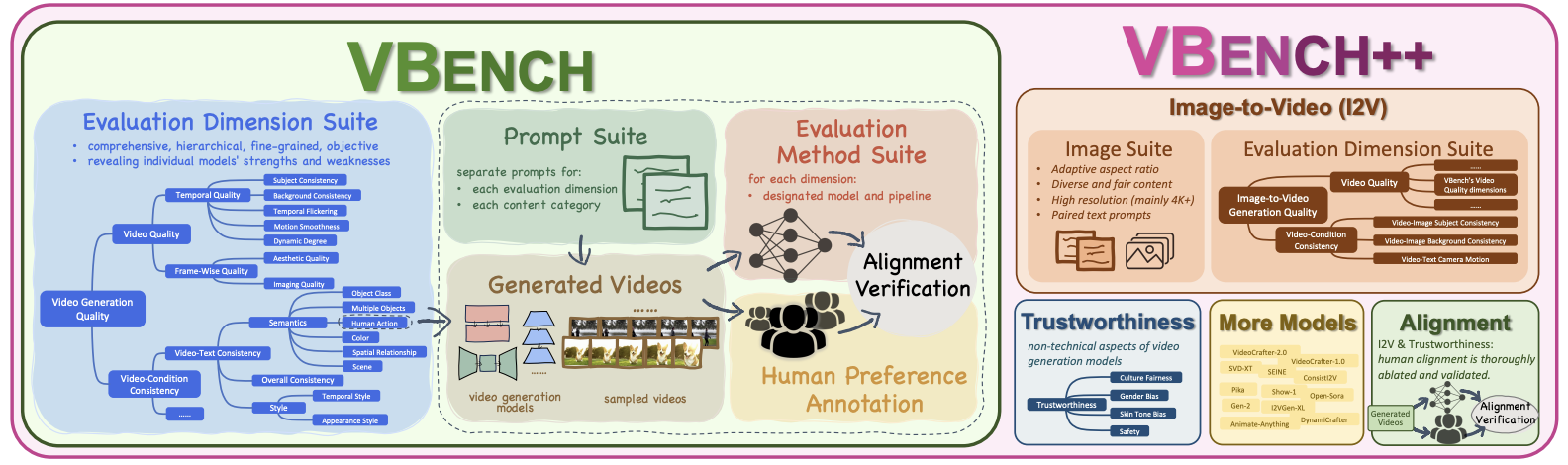
VBench++: Comprehensive and Versatile Benchmark Suite for Video Generative Models
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, Ziwei Liu
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2025
[Paper] [Code]
Ziqi Huang, Fan Zhang, Xiaojie Xu, Yinan He, Jiashuo Yu, Ziyue Dong, Qianli Ma, Nattapol Chanpaisit, Chenyang Si, Yuming Jiang, Yaohui Wang, Xinyuan Chen, Ying-Cong Chen, Limin Wang, Dahua Lin, Yu Qiao, Ziwei Liu
IEEE Transactions on Pattern Analysis and Machine Intelligence (TPAMI) 2025
[Paper] [Code]
CVPR 2025

Cinemo: Consistent and Controllable Image Animation with Motion Diffusion Models
Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Tien-Tsin Wong, Yuan-Fang Li, Cunjian Chen, Yu Qiao
CVPR 2025
[Paper] [Project Page] [Code]
Xin Ma, Yaohui Wang, Gengyun Jia, Xinyuan Chen, Tien-Tsin Wong, Yuan-Fang Li, Cunjian Chen, Yu Qiao
CVPR 2025
[Paper] [Project Page] [Code]
IJCV 2025

Leo: Generative Latent Image Animator for Human Video Synthesis
Yaohui Wang, Xin Ma, Xinyuan Chen, Cunjian Chen, Antitza Dantcheva, Bo Dai, Yu Qiao
International Journal of Computer Vision (IJCV) 2025
[Paper] [Project Page] [Code]
Yaohui Wang, Xin Ma, Xinyuan Chen, Cunjian Chen, Antitza Dantcheva, Bo Dai, Yu Qiao
International Journal of Computer Vision (IJCV) 2025
[Paper] [Project Page] [Code]
CVPR 2025

Ouroboros3D: Image-to-3D Generation via 3D-Aware Recursive Diffusion
Hao Wen, Ziqi Huang, Yaohui Wang, Xinyuan Chen, Lu Sheng
CVPR 2025
[Paper] [Project Page] [Code]
Hao Wen, Ziqi Huang, Yaohui Wang, Xinyuan Chen, Lu Sheng
CVPR 2025
[Paper] [Project Page] [Code]
CVPR 2025
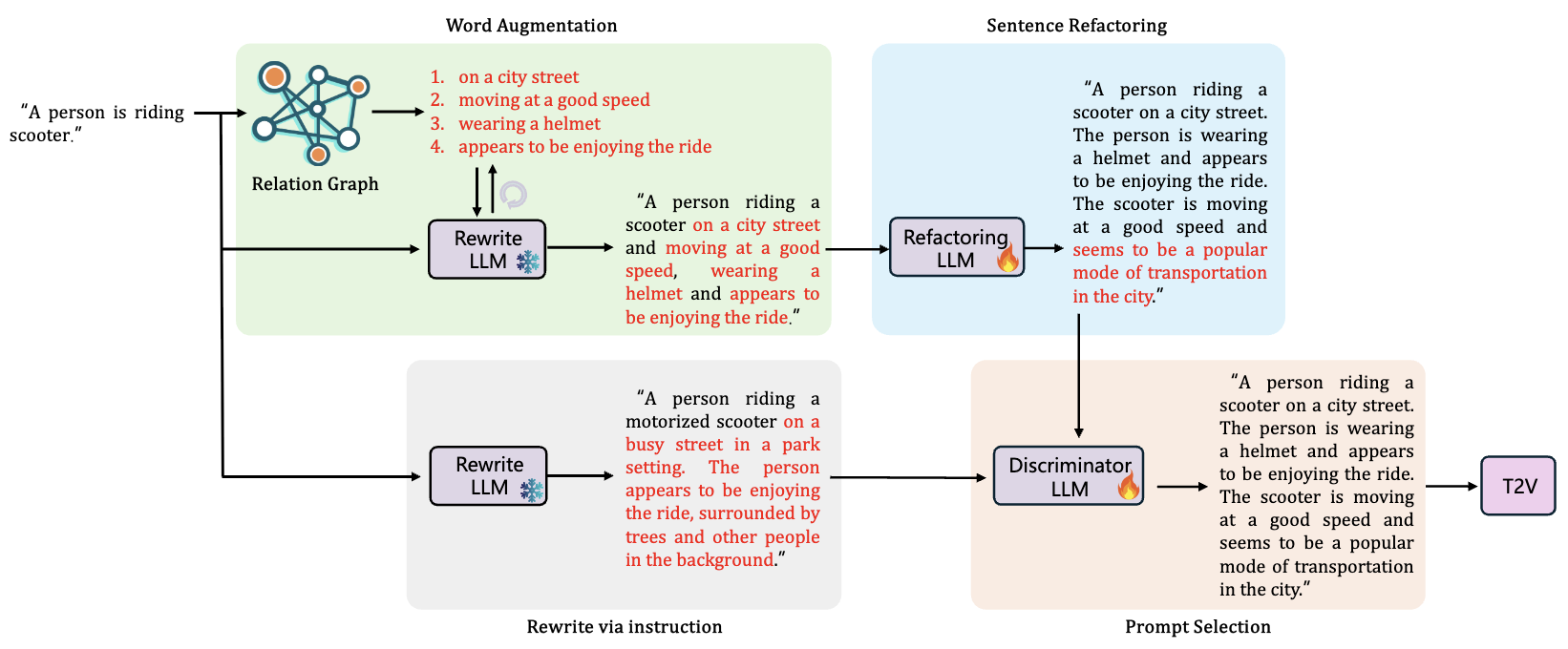
The Devil Is in the Prompts: Retrieval-Augmented Prompt Optimization for Text-to-Video Generation
Bingjie Gao, Xinyu Gao, Xiaoxue Wu, Yujie Zhou, Yu Qiao, Li Niu, Xinyuan Chen, Yaohui Wang
CVPR 2025
[Paper] [Project Page]
Bingjie Gao, Xinyu Gao, Xiaoxue Wu, Yujie Zhou, Yu Qiao, Li Niu, Xinyuan Chen, Yaohui Wang
CVPR 2025
[Paper] [Project Page]
Vinci: A Real-time Smart Assistant Based on Egocentric Vision-Language Model for Portable Devices
Yifei Huang, Jilan Xu, Baoqi Pei, Lijin Yang, Mingfang Zhang, Yinan He, Guo Chen, Xinyuan Chen, Yaohui Wang, et al.
IMWUT / ACM UbiComp 2025
Yifei Huang, Jilan Xu, Baoqi Pei, Lijin Yang, Mingfang Zhang, Yinan He, Guo Chen, Xinyuan Chen, Yaohui Wang, et al.
IMWUT / ACM UbiComp 2025
Timestep Master: Asymmetrical Mixture of Timestep LoRA Experts for Versatile and Efficient Diffusion Models in Vision
Shaobin Zhuang, Yiwei Guo, Yanbo Ding, Kunchang Li, Xinyuan Chen, Yaohui Wang, Fangyikang Wang, Yixiao Zhang, Chunhua Li, et al.
ICML 2025
[Paper]
Shaobin Zhuang, Yiwei Guo, Yanbo Ding, Kunchang Li, Xinyuan Chen, Yaohui Wang, Fangyikang Wang, Yixiao Zhang, Chunhua Li, et al.
ICML 2025
[Paper]
arXiv 2025

AccVideo: Accelerating Video Diffusion Model with Synthetic Dataset
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, Yu Qiao
arXiv:2503.19462, 2025
[Paper] [Project Page] [Code]
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, Yu Qiao
arXiv:2503.19462, 2025
[Paper] [Project Page] [Code]
Diff-TST: Diffusion Model for One-Shot Text-Image Style Transfer
Sizhe Pang, Xinyuan Chen, Yangchen Xie, Hongjian Zhan, Bing Yin, Yue Lu
Expert Systems with Applications, vol. 263, 125747, 2025
Sizhe Pang, Xinyuan Chen, Yangchen Xie, Hongjian Zhan, Bing Yin, Yue Lu
Expert Systems with Applications, vol. 263, 125747, 2025
An Egocentric Vision-Language Model Based Portable Real-time Smart Assistant
Yifei Huang, Jilan Xu, Baoqi Pei, Yinan He, Guo Chen, Mingfang Zhang, Lijin Yang, Zheng Nie, Jinyao Liu, Guoshun Fan, et al.
arXiv:2503.04250, 2025
Yifei Huang, Jilan Xu, Baoqi Pei, Yinan He, Guo Chen, Mingfang Zhang, Lijin Yang, Zheng Nie, Jinyao Liu, Guoshun Fan, et al.
arXiv:2503.04250, 2025
arXiv 2025

Lia-X: Interpretable Latent Portrait Animator
Yaohui Wang, Di Yang, Xinyuan Chen, Francois Bremond, Yu Qiao, Antitza Dantcheva
arXiv:2508.09959, 2025
[Paper] [Project Page] [Code]
Yaohui Wang, Di Yang, Xinyuan Chen, Francois Bremond, Yu Qiao, Antitza Dantcheva
arXiv:2508.09959, 2025
[Paper] [Project Page] [Code]
arXiv 2025

GenHOI: Generalizing Text-driven 4D Human-Object Interaction Synthesis for Unseen Objects
Shujia Li, Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Yixing Ban
arXiv:2506.15483, 2025
[Paper] [Project Page] [Code]
Shujia Li, Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Yixing Ban
arXiv:2506.15483, 2025
[Paper] [Project Page] [Code]
Training-Free Stylized Text-to-Image Generation with Fast Inference
Xin Ma, Yaohui Wang, Xinyuan Chen, Tien-Tsin Wong, Cunjian Chen
arXiv:2505.19063, 2025
Xin Ma, Yaohui Wang, Xinyuan Chen, Tien-Tsin Wong, Cunjian Chen
arXiv:2505.19063, 2025
arXiv 2025

RAPO++: Cross-Stage Prompt Optimization for Text-to-Video Generation via Data Alignment and Test-Time Scaling
Bingjie Gao, Qianli Ma, Xiaoxue Wu, Shuai Yang, Guanzhou Lan, Hanzhe Zhao, Jiabei Chen, Qifeng Liu, Yu Qiao, Xinyuan Chen, Yaohui Wang
arXiv:2510.20206, 2025
[Paper] [Project Page] [Code]
Bingjie Gao, Qianli Ma, Xiaoxue Wu, Shuai Yang, Guanzhou Lan, Hanzhe Zhao, Jiabei Chen, Qifeng Liu, Yu Qiao, Xinyuan Chen, Yaohui Wang
arXiv:2510.20206, 2025
[Paper] [Project Page] [Code]
2024
TMLR 2025

Latte: Latent Diffusion Transformer for Video Generation
Xin Ma, Yaohui Wang, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, Yu Qiao
arXiv:2401.03048, 2024 (TMLR 2025)
[Paper] [Project Page] [Code]
Xin Ma, Yaohui Wang, Xinyuan Chen, Gengyun Jia, Ziwei Liu, Yuan-Fang Li, Cunjian Chen, Yu Qiao
arXiv:2401.03048, 2024 (TMLR 2025)
[Paper] [Project Page] [Code]
CVPR 2024
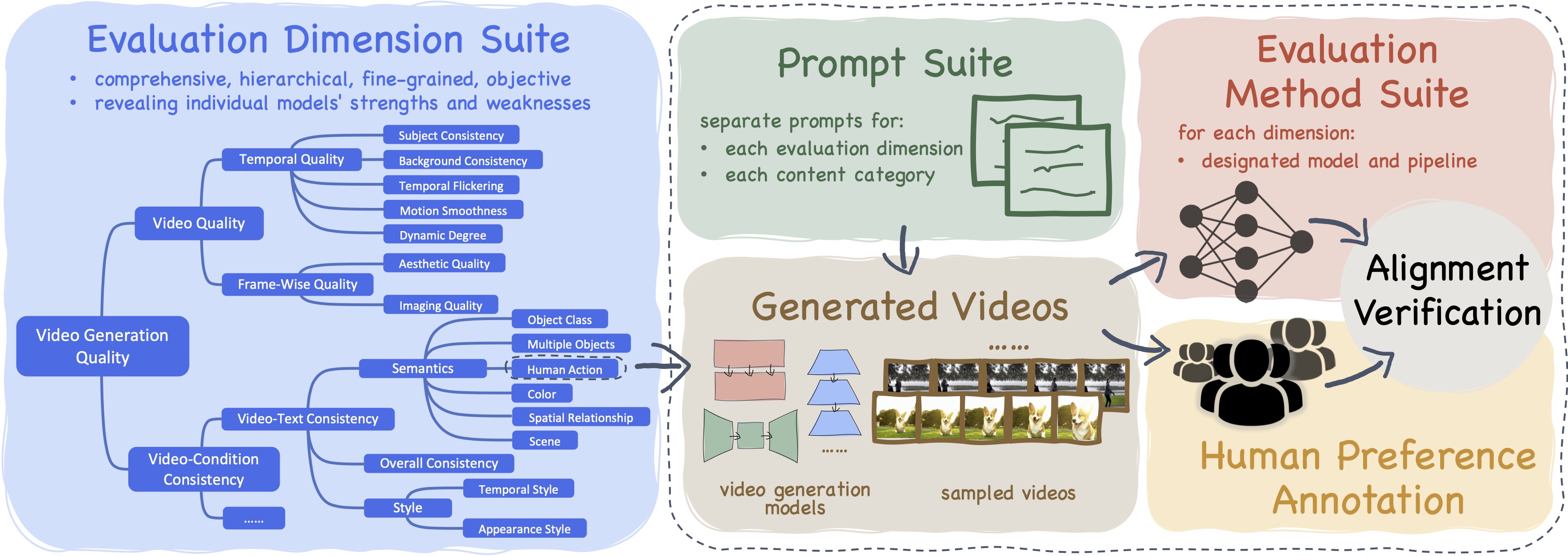
VBench: Comprehensive Benchmark Suite for Video Generative Models
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, Ziwei Liu
CVPR 2024 Highlight
[Paper] [Project Page] [Code]
Ziqi Huang, Yinan He, Jiashuo Yu, Fan Zhang, Chenyang Si, Yuming Jiang, Yuanhan Zhang, Tianxing Wu, Qingyang Jin, Nattapol Chanpaisit, Yaohui Wang, Xinyuan Chen, Limin Wang, Dahua Lin, Yu Qiao, Ziwei Liu
CVPR 2024 Highlight
[Paper] [Project Page] [Code]
CVPR 2024
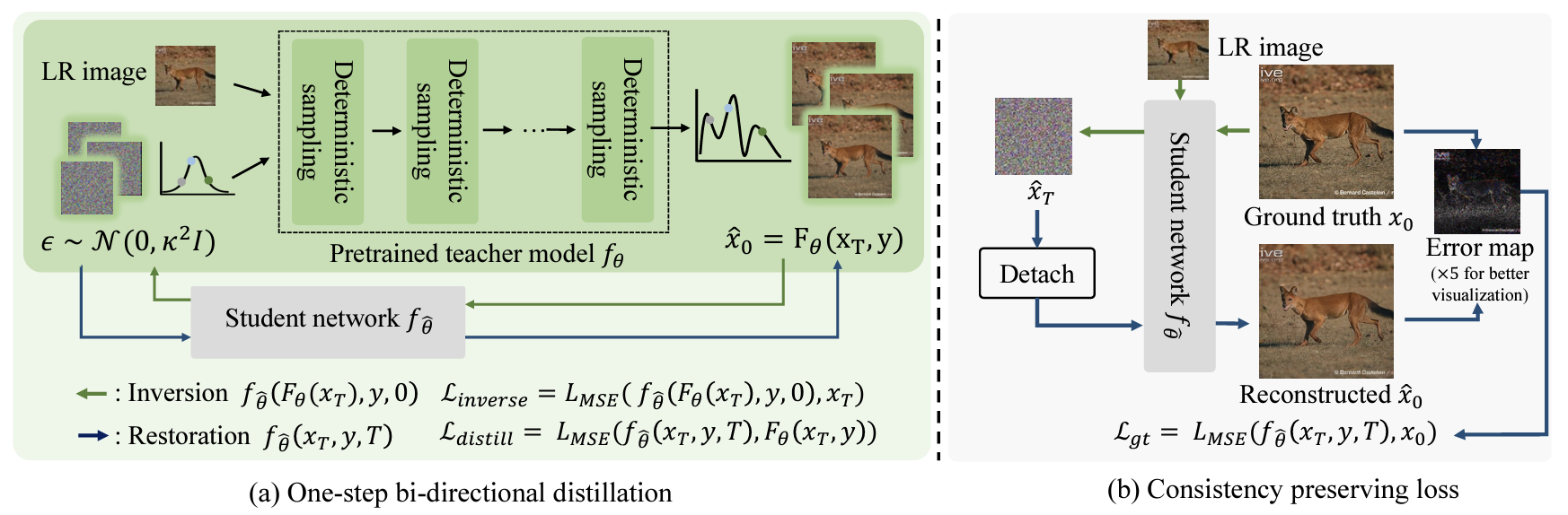
CVPR 2024

Vlogger: Make Your Dream A Vlog
Shaobin Zhuang, Kunchang Li, Xinyuan Chen*, Yaohui Wang*, Ziwei Liu, Yu Qiao, Yali Wang*
CVPR 2024
[Paper] [Project Page] [Code]
Shaobin Zhuang, Kunchang Li, Xinyuan Chen*, Yaohui Wang*, Ziwei Liu, Yu Qiao, Yali Wang*
CVPR 2024
[Paper] [Project Page] [Code]
NeurIPS 2024

4Diffusion: Multi-view Video Diffusion Model for 4D Generation
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, Yu Qiao
NeurIPS 2024
[Paper] [Project Page] [Code]
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, Yu Qiao
NeurIPS 2024
[Paper] [Project Page] [Code]
CVPR 2024

EpiDiff: Enhancing Multi-View Synthesis via Localized Epipolar-Constrained Diffusion
Zehuan Huang, Hao Wen, Junting Dong, Yaohui Wang, Yangguang Li, Xinyuan Chen, Yan-Pei Cao, Ding Liang, Yu Qiao, Bo Dai, Lu Sheng
CVPR 2024
[Paper] [Project Page]
Zehuan Huang, Hao Wen, Junting Dong, Yaohui Wang, Yangguang Li, Xinyuan Chen, Yan-Pei Cao, Ding Liang, Yu Qiao, Bo Dai, Lu Sheng
CVPR 2024
[Paper] [Project Page]
AAAI 2024

Brush Your Text: Synthesize Any Scene Text on Images via Diffusion Model
Lingjun Zhang*, Xinyuan Chen*, Yaohui Wang, Yue Lu, Yu Qiao
AAAI 2024
[Paper]
Lingjun Zhang*, Xinyuan Chen*, Yaohui Wang, Yue Lu, Yu Qiao
AAAI 2024
[Paper]
AAAI 2024
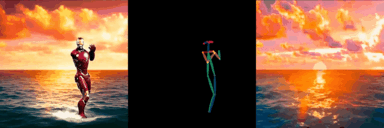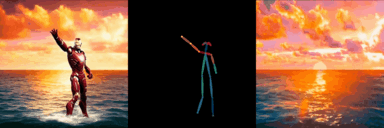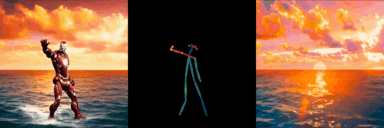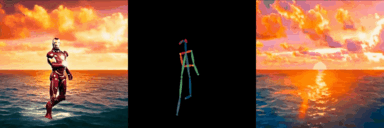
ConditionVideo: Training-Free Condition-Guided Video Generation
Bo Peng, Xinyuan Chen*, Yaohui Wang, Chaochao Lu, Yu Qiao
AAAI 2024
[Paper] [Project Page] [Code]
Bo Peng, Xinyuan Chen*, Yaohui Wang, Chaochao Lu, Yu Qiao
AAAI 2024
[Paper] [Project Page] [Code]
Vinci: A Real-time Embodied Smart Assistant Based on Egocentric Vision-Language Model
Yifei Huang, Jilan Xu, Baoqi Pei, Yinan He, Guo Chen, Lijin Yang, Xinyuan Chen, Yaohui Wang, Zheng Nie, et al.
arXiv:2412.21080, 2024
Yifei Huang, Jilan Xu, Baoqi Pei, Yinan He, Guo Chen, Lijin Yang, Xinyuan Chen, Yaohui Wang, Zheng Nie, et al.
arXiv:2412.21080, 2024
WACV 2024

Hierarchical Diffusion Autoencoders and Disentangled Image Manipulation
Zeyu Lu, Chengyue Wu, Xinyuan Chen, Yaohui Wang, Lei Bai, Yu Qiao, Xihui Liu
WACV 2024
Zeyu Lu, Chengyue Wu, Xinyuan Chen, Yaohui Wang, Lei Bai, Yu Qiao, Xihui Liu
WACV 2024
Uncertainty-aware Image Inpainting with Adaptive Feedback Network
Xin Ma, Xiaoqiang Zhou, Huaibo Huang, Gengyun Jia, Yaohui Wang, Xinyuan Chen, Cunjian Chen
Expert Systems with Applications, vol. 235, 121148, 2024
Xin Ma, Xiaoqiang Zhou, Huaibo Huang, Gengyun Jia, Yaohui Wang, Xinyuan Chen, Cunjian Chen
Expert Systems with Applications, vol. 235, 121148, 2024
Combinatorial Progressive Architecture Search for Crowd Counting
Qian Li, Chao Ma, Hongwei Chen, Xinyuan Chen, Xiaokang Yang
Displays, vol. 83, 102686, 2024
Qian Li, Chao Ma, Hongwei Chen, Xinyuan Chen, Xiaokang Yang
Displays, vol. 83, 102686, 2024
2023
ICLR 2024

SEINE: Short-to-Long Video Diffusion Model for Generative Transition and Prediction
Xinyuan Chen, Yaohui Wang, Lingjun Zhang, Shaobin Zhuang, Xin Ma, Jiashuo Yu, Yali Wang, Dahua Lin, Yu Qiao, Ziwei Liu
ICLR 2024 Spotlight
[Paper] [Project Page] [Code]
Xinyuan Chen, Yaohui Wang, Lingjun Zhang, Shaobin Zhuang, Xin Ma, Jiashuo Yu, Yali Wang, Dahua Lin, Yu Qiao, Ziwei Liu
ICLR 2024 Spotlight
[Paper] [Project Page] [Code]
IJCV 2024

LaVie: High-Quality Video Generation with Cascaded Latent Diffusion Models
Yaohui Wang*, Xinyuan Chen*, Xin Ma*, Shangchen Zhou, Ziqi Huang, Yi Wang, Ceyuan Yang, Yinan He, Jiashuo Yu, Peiqing Yang, Yuwei Guo, Tianxing Wu, Chenyang Si, Yuming Jiang, Cunjian Chen, Chen Change Loy, Bo Dai, Dahua Lin, Yu Qiao, Ziwei Liu
arXiv:2309.15103, 2023 (IJCV 2024)
[Paper] [Project Page] [Code]
Yaohui Wang*, Xinyuan Chen*, Xin Ma*, Shangchen Zhou, Ziqi Huang, Yi Wang, Ceyuan Yang, Yinan He, Jiashuo Yu, Peiqing Yang, Yuwei Guo, Tianxing Wu, Chenyang Si, Yuming Jiang, Cunjian Chen, Chen Change Loy, Bo Dai, Dahua Lin, Yu Qiao, Ziwei Liu
arXiv:2309.15103, 2023 (IJCV 2024)
[Paper] [Project Page] [Code]
InternVid: A Large-scale Video-Text Dataset for Multimodal Understanding and Generation
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, Conghui He, Ping Luo, Ziwei Liu, Yali Wang, Limin Wang, Yu Qiao
ICLR 2024
[Paper]
Yi Wang, Yinan He, Yizhuo Li, Kunchang Li, Jiashuo Yu, Xin Ma, Xinhao Li, Guo Chen, Xinyuan Chen, Yaohui Wang, Conghui He, Ping Luo, Ziwei Liu, Yali Wang, Limin Wang, Yu Qiao
ICLR 2024
[Paper]
ICML 2023
Long-term Rhythmic Video Soundtracker
Jiashuo Yu, Yaohui Wang, Xinyuan Chen, Xiao Sun, Yu Qiao
ICML 2023
[Paper]
Jiashuo Yu, Yaohui Wang, Xinyuan Chen, Xiao Sun, Yu Qiao
ICML 2023
[Paper]
Weakly Supervised Scene Text Generation for Low-Resource Languages
Yangchen Xie*, Xinyuan Chen*, Hongjian Zhan, Palaiahnakote Shivakumara, Bing Yin, Cheng-Lin Liu, Yue Lu
Expert Systems with Applications, 121622, 2023
Yangchen Xie*, Xinyuan Chen*, Hongjian Zhan, Palaiahnakote Shivakumara, Bing Yin, Cheng-Lin Liu, Yue Lu
Expert Systems with Applications, 121622, 2023
Multi-level Feature Disentanglement Network for Cross-dataset Face Forgery Detection
Zicheng Fu, Xinyuan Chen, Donglai Liu, Xiaolong Qu, Jiashuo Dong, Xiang Zhang, Sheng Ji
Image and Vision Computing, vol. 135, 104686, 2023
Zicheng Fu, Xinyuan Chen, Donglai Liu, Xiaolong Qu, Jiashuo Dong, Xiang Zhang, Sheng Ji
Image and Vision Computing, vol. 135, 104686, 2023
2022
Cross Attention Based Style Distribution for Controllable Person Image Synthesis
Xinyue Zhou, Mingyu Yin, Xinyuan Chen, Li Sun, Changxin Gao, Qingli Li
ECCV 2022
[Paper]
Xinyue Zhou, Mingyu Yin, Xinyuan Chen, Li Sun, Changxin Gao, Qingli Li
ECCV 2022
[Paper]
Diff-Font: Diffusion Model for Robust One-Shot Font Generation
Haibin He*, Xinyuan Chen*, Chaoyue Wang, Juhua Liu, Bo Du, Dacheng Tao, Yu Qiao
arXiv:2212.05895, 2022
[Paper]
Haibin He*, Xinyuan Chen*, Chaoyue Wang, Juhua Liu, Bo Du, Dacheng Tao, Yu Qiao
arXiv:2212.05895, 2022
[Paper]
DG-Font++: Robust Deformable Generative Networks for Unsupervised Font Generation
Xinyuan Chen, Yangchen Xie, Li Sun, Yue Lu
arXiv:2212.14742, 2022
[Paper]
Xinyuan Chen, Yangchen Xie, Li Sun, Yue Lu
arXiv:2212.14742, 2022
[Paper]
Unsupervised Image Restoration with Quality-Task-Perception Loss
Wenchao Xu, Xinyuan Chen*, Huaijin Guo, Xinjian Huang, Wen Liu
IEEE Transactions on Circuits and Systems for Video Technology, vol. 32(9), 5736-5747, 2022
Wenchao Xu, Xinyuan Chen*, Huaijin Guo, Xinjian Huang, Wen Liu
IEEE Transactions on Circuits and Systems for Video Technology, vol. 32(9), 5736-5747, 2022
2021
DG-Font: Deformable Generative Networks for Unsupervised Font Generation
Yangchen Xie, Xinyuan Chen*, Li Sun, Yue Lu
CVPR 2021
[Paper]
Yangchen Xie, Xinyuan Chen*, Li Sun, Yue Lu
CVPR 2021
[Paper]
Multi-order Adversarial Representation Learning for Composed Query Image Retrieval
Zicheng Fu*, Xinyuan Chen*, Jiashuo Dong, Sheng Ji
ICASSP 2021
Zicheng Fu*, Xinyuan Chen*, Jiashuo Dong, Sheng Ji
ICASSP 2021
Swin-Spectral Transformer for Cholangiocarcinoma Hyperspectral Image Segmentation
Zijun Zhou, Shiqi Qiu, Yaohui Wang, Mei Zhou, Xinyuan Chen, Menghan Hu, Qingli Li, Yue Lu
ICISP BMEI 2021
Zijun Zhou, Shiqi Qiu, Yaohui Wang, Mei Zhou, Xinyuan Chen, Menghan Hu, Qingli Li, Yue Lu
ICISP BMEI 2021
Scene Text Transfer for Cross-Language
Lingjun Zhang, Xinyuan Chen, Yangchen Xie, Yue Lu
International Conference on Image and Graphics (ICIG) 2021
Lingjun Zhang, Xinyuan Chen, Yangchen Xie, Yue Lu
International Conference on Image and Graphics (ICIG) 2021
Bijective Multi-mode Deraining on Single Image
Shiqi Qiu, Wenchao Xu, Li Sun, Guangtao Zhai, Xinyuan Chen, Qingli Li
ICISP BMEI 2021
Shiqi Qiu, Wenchao Xu, Li Sun, Guangtao Zhai, Xinyuan Chen, Qingli Li
ICISP BMEI 2021
Deformable Generative Networks for Few-shot Cross-Language Font Generation
Yangchen Xie, Xinyuan Chen, Lingjun Zhang, Li Sun, Yue Lu
27th ACM SIGKDD Workshop on Model Mining, 2021
Yangchen Xie, Xinyuan Chen, Lingjun Zhang, Li Sun, Yue Lu
27th ACM SIGKDD Workshop on Model Mining, 2021
2020
Long-term Video Prediction via Criticization and Retrospection
Xinyuan Chen, Chang Xu, Xiaokang Yang, Dacheng Tao
IEEE Transactions on Image Processing (TIP), vol. 29, 7090-7103, 2020
Xinyuan Chen, Chang Xu, Xiaokang Yang, Dacheng Tao
IEEE Transactions on Image Processing (TIP), vol. 29, 7090-7103, 2020
2019
Adversarial Watermarking to Attack Deep Neural Networks
Gengxing Wang, Xinyuan Chen, Chang Xu
ICASSP 2019
Gengxing Wang, Xinyuan Chen, Chang Xu
ICASSP 2019
2018
Attention-GAN for Object Transfiguration in Wild Images
Xinyuan Chen, Chang Xu, Xiaokang Yang, Dacheng Tao
ECCV 2018
[Paper]
Xinyuan Chen, Chang Xu, Xiaokang Yang, Dacheng Tao
ECCV 2018
[Paper]
Gated-GAN: Adversarial Gated Networks for Multi-Collection Style Transfer
Xinyuan Chen, Chang Xu, Xiaokang Yang, Li Song, Dacheng Tao
IEEE Transactions on Image Processing (TIP), vol. 28(2), 546-560, 2018
Xinyuan Chen, Chang Xu, Xiaokang Yang, Li Song, Dacheng Tao
IEEE Transactions on Image Processing (TIP), vol. 28(2), 546-560, 2018
2016
Deep RNNs for Video Denoising
Xinyuan Chen, Li Song, Xiaokang Yang
Applications of Digital Image Processing XXXIX, vol. 9971, 573-582, 2016
Xinyuan Chen, Li Song, Xiaokang Yang
Applications of Digital Image Processing XXXIX, vol. 9971, 573-582, 2016